There are many aspects of creating software that ranges through source control, code convention, testing, etc. In this section we are primarily interesting in making binary executables out of source code and to a lesser extends deploying those executables to a production system.
Why should I understand builds?
Programming usually evolves around Edit-Build-Test cycles. Typically there are two noticeable such cycles. The first one is an incremental Edit-Build-Test cycle, run by contributors writing and debugging features in their own workspace. The time spent in incremental builds has a direct impact on an engineer's productivity. The second cycle is a full Edit-Build-Test cycle, typically executed by integration, release and quality teams. The time spent there on full builds usually impacts the productivity of everyone on the team.
From a management perspective builds are related to productivity. As an engineer, things you do not understand are unresting and since builds represents one third of the daily routine, you defintely want to know what is going on under the hood.
A simple problem at the heart of "make"
This section uses make as a generic term and concepts equivalently apply to other tools in that category such as ant, scons, etc. To understand the foundation of make, let's look into a simple problem:
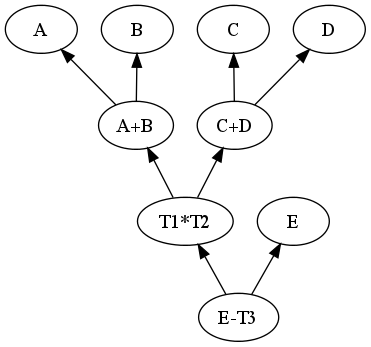
Compute R where
R = E - ((A + B) * (C + D))
and
A = 3, B = 2, C = 5, D = 7, E = 71.
Then update A to 1 and compute R again.
When given this problem, a common approach is to write a sequence of instructions. This is known as imperative programming or, in our build terminology the "bash" approach.
| Initial execution | |
|---|---|
| Sequence of instructions | Execution trace |
|
|
| Execution after update | |
| Sequence of instructions | Execution trace |
|
|
As we can see, the "bash" approach executes the whole script even in the presence of a simple update. Obviously we can do better than that. If instead of specifying imperatively a sequence of instructions to follow we instead specify the relationship between all final and intermediate results, we can then devise a dependency traversal algorithm that will cache the intermediate results and only update the appropriate nodes when required. We can also write this algorithm to take advantage of the multi-processors currently available in most modern systems to update nodes in parallel. We will call it the "make" approach.
| Initial execution | |
|---|---|
| Sequence of instructions | Execution trace |
|
|
| Execution after update | |
| Sequence of instructions | Execution trace |
|
|
|
A conceptual leap
Mainstream languages (C, C++, Java, Python) encourages an imperative approach to programming: first do this, then do that, ... Programming in make requires a conceptual leap. Makefiles do not specify sequence of instructions to be executed but how commands relate to each other. It is then up to the make algorithm to recompute intermediate results as needed using parallel and out-of-order execution as fit.
As a direct result issues dealing with make usually involve either mapping log output to the Makefile source code or figuring out dependencies specification. Writing Makefiles has a lot in common understanding multi-processor programming!
An actual problem
You have been tasked to deliver a major Linux distribution from scratch. You will have to compile somewhere around 100,000 inter-dependent projects (current Ubuntu estimates). A sequential approach leads to build times in days and weeks. With a graph of that magnitude computing an acceptable graph traversal is already time consuming. The graph is a few order of magnitude more when you consider specification of source and header files dependencies for each project. Finally a single implicit dependency might break a parallel build as seen before.
At that point specifying, organizing and managing dependencies becomes the most complex problem.
A Hierarchy of dependencies
So how do we do it? We decompose the task between inter-project dependencies and intra-project dependencies. Both problems are very much related but except for ports tree implementation, we will deal with them using different tools: a package manager tool such as rpm or aptitude for the projects graph and make for the in-project targets graph. The notion of project and hierarchical project dependencies help manage complexity. They are not real though. Only direct dependencies on installed file exists so we need a way to between inter- and intra- dependencies levels. That is where configure comes into play.
portFind and recursively install all prerequisite projects.
Find prerequisites that are outside the project and initialize Makefile accordingly.
Make targets from intra-project dependencies.
Install executables and libraries so they can be found by configure scripts.
Drop a workspace management script
In today's environment, the number of third-party dependencies for any piece of software is staggering. Most modern operating systems come with package managers whose goal is to get all the runtime dependencies correct. Package managers greatly lack the flexiblity required for code development as the activity often involve compiling a project with different sets of tool and library versions. Those need to be installed alongside each other and alongside the stable runtime on a development machine. Once all third-party executables, headers, libraries, etc. have been installed and configured, it is time to build the code. With a substantial source code base, this usually involves intricate recursive calls to "make" and a complex set of implicit dependencies. The result are build systems with a tendency to create broken builds despite best efforts to enforce conventions in hope of improving quality.
A workspace manager application is used to setup a contributor's system with third-party prerequisites and source code under revision control such that it is possible to execute a development cycle (edit/build/run) on a local machine. As such, the workspace manager application integrates functionality usually found in package managers, configure scripts and make together in a single consistent bundle.
Drop is an inter-project dependencies tool (dws), a set of makefile fragments and conventions used at fortylines to improve the quality and robustness of building a large source repository. Its efficiency is measured by the time it takes to setup a random machine for code development first and subsequently the time spent in rebuilding the source base after any changes.
One command to rule them all
As we have seen before, there are two build cycles that matter day-in day-out, an incremental make for development cycles and a full build for exhaustive test cycles. Both use cases must be supported by a single simple command line otherwise there is little chance tests will actually be executed and results could be reproduced.
For example, drop provides "dws make" for incremental development cycles. This command is mostly a wrapper on top of make with logging facilities.
For example drop provides "dws build" full build for exhaustive test cycles. The command will remove the *siteTop*, update *srcTop* from the remote repostiory, optionally patch the source tree, recursively re-make all projects and send an email report.
There are also hybrid commands such as "dws make recurse" (recursively re-make all prerequisites projects) and "dws build --noclean" to run an update, patch, re-make, report cycle (skip remove). These commands are useful at times for specific cases.
Snapshot builds
In order to do extensive testing, it should be straightforward to build the repository from an bare installation of any operating system. This means after downloading and installing the .iso file found on your favorite distribution's website, there should be only one command to execute. dws build will fetch fortylines' repository, compile it and report the results to the server. It is accomplished with a single command run on the local machine:
dws build http://fortylines.com/reps/worlds.git